Hay dos formas de escribir uniones entre tablas usando data.table. La primera es mediante la función merge() de r base. Los argumentos básicos de esta función son:
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE,
incomparables = NULL, ...)
x, y = son los objetos data.table que se quieren unir
by, by.x, by.y = nombres de las columnas que funcionan como índice para hacer la unión. Cuando ambas tablas tienen el mismo nombre de columna se utiliza by, cuando no, se puede especificar el nombre en x (by.x) y el nombre en y (by.y)
all, all.x, all.y = especifican el tipo de unión. all = T es para hacer full join (mantiene todas las filas de ambas tablas), all.x = T es para hacer left join (mantiene todas las filas de la tabla x), all.y es para hacer right join (mantiene todas las filas de y), all = F es para hacer inner join (solo mantiene las filas que están en ambas tablas)
id letter1
<int> <char>
1: 1 A
2: 2 A
3: 3 F
4: 4 I
5: 5 A
6: 6 B
7: 7 E
8: 8 I
9: 9 I
10: 10 J
dt2
id letter2
<int> <char>
1: 6 H
2: 7 A
3: 8 E
4: 9 G
5: 10 C
6: 11 I
7: 12 G
8: 13 A
9: 14 C
10: 15 F
# inner joinmerge(dt1,dt2,by ="id")
Key: <id>
id letter1 letter2
<int> <char> <char>
1: 6 B H
2: 7 E A
3: 8 I E
4: 9 I G
5: 10 J C
# left joinmerge(dt1,dt2,by ="id", all.x = T)
Key: <id>
id letter1 letter2
<int> <char> <char>
1: 1 A <NA>
2: 2 A <NA>
3: 3 F <NA>
4: 4 I <NA>
5: 5 A <NA>
6: 6 B H
7: 7 E A
8: 8 I E
9: 9 I G
10: 10 J C
# right joinmerge(dt1,dt2,by ="id", all.y = T)
Key: <id>
id letter1 letter2
<int> <char> <char>
1: 6 B H
2: 7 E A
3: 8 I E
4: 9 I G
5: 10 J C
6: 11 <NA> I
7: 12 <NA> G
8: 13 <NA> A
9: 14 <NA> C
10: 15 <NA> F
# full joinmerge(dt1,dt2,by ="id", all = T)
Key: <id>
id letter1 letter2
<int> <char> <char>
1: 1 A <NA>
2: 2 A <NA>
3: 3 F <NA>
4: 4 I <NA>
5: 5 A <NA>
6: 6 B H
7: 7 E A
8: 8 I E
9: 9 I G
10: 10 J C
11: 11 <NA> I
12: 12 <NA> G
13: 13 <NA> A
14: 14 <NA> C
15: 15 <NA> F
Sintaxis de data.table
La segunda forma de hacer uniones entre tablas es usando la sintaxis de data.table.
DT1[DT2, nomatch = 0]
Si lo traducimos a la sintaxis de la función anterior entonces la tabla que está por fuera es x, la tabla que está por dentro es y y el argumento nomatch te permite indicar qué hacer con las claves para las que no encuentra coincidencia en ambas tablas. Cuando nomatch = 0 no incluye las claves que no se comparten entre tablas.
# inner joindt1[dt2, on ="id", nomatch=0]
id letter1 letter2
<int> <char> <char>
1: 6 B H
2: 7 E A
3: 8 I E
4: 9 I G
5: 10 J C
# left joindt1[dt2, on ="id"]
id letter1 letter2
<int> <char> <char>
1: 6 B H
2: 7 E A
3: 8 I E
4: 9 I G
5: 10 J C
6: 11 <NA> I
7: 12 <NA> G
8: 13 <NA> A
9: 14 <NA> C
10: 15 <NA> F
# right joindt2[dt1, on ="id"]
id letter2 letter1
<int> <char> <char>
1: 1 <NA> A
2: 2 <NA> A
3: 3 <NA> F
4: 4 <NA> I
5: 5 <NA> A
6: 6 H B
7: 7 A E
8: 8 E I
9: 9 G I
10: 10 C J
Ejercicio
Para el siguiente ejercicio vamos a cargar varias tablas. Representan la información de muchas canciones de Spotify. A diferencia de la tabla que hemos estado utilizando estas canciones son de musica electrónica de la compañía Beatport. Las tablas fueron descargadas de la siguiente página
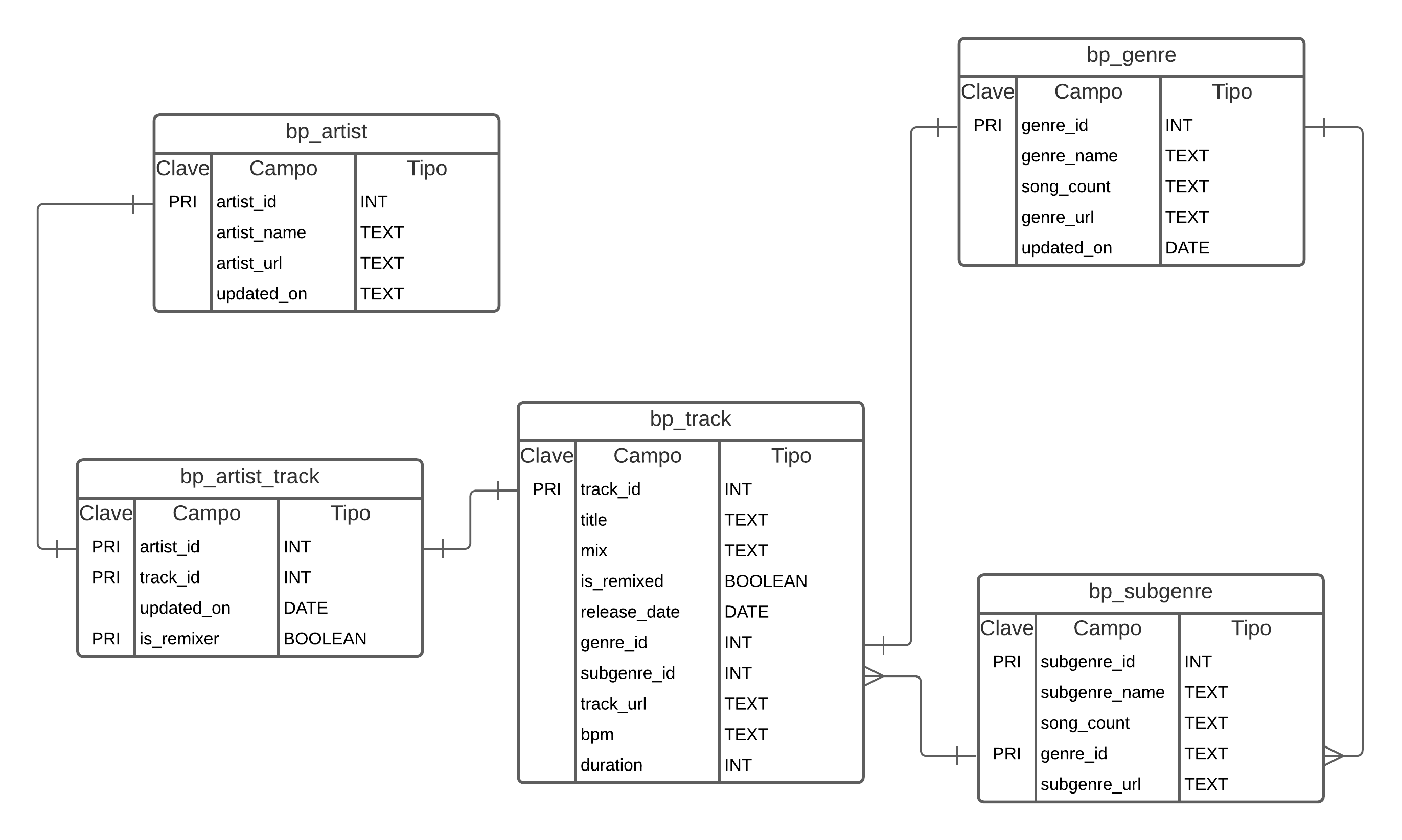
Las tablas se relacionan de la siguiente manera:
Nota: El objeto de tracks tiene 10M+ de filas, pesa 2.6 GB cuando está cargado en memoria. Si tu computadora tiene poca memoria puedes elegir no juntar todos los archivos de las canciones (por ejemplo tracks <- do.call(rbind,data_files[5:6]) para solo cargar dos de los 4 archivos)
# Enlistar los archivos de canciones (guardados en la carpeta de tracks)tracks <-list.files("data/bd/tracks", full.names = T)# Enlistar los archivos restantes en la carpeta bdfiles <-c(list.files("data/bd", full.names = T, pattern =".csv*"), tracks)# Leer los archivos usando freaddata_files <-lapply(files,fread)names(data_files) <-c(list.files("data/bd", pattern =".csv*"), list.files("data/bd/tracks"))# Guardar los datos en objetos diferentesgenre <- data_files$bp_genre.csvsubgenre <- data_files$bp_subgenre.csvartist <- data_files$bp_artist.csv.gzartist_track <- data_files$bp_artist_track.csv.gztracks <-do.call(rbind,data_files[5:8])# Borrar la lista de archivosrm(data_files)
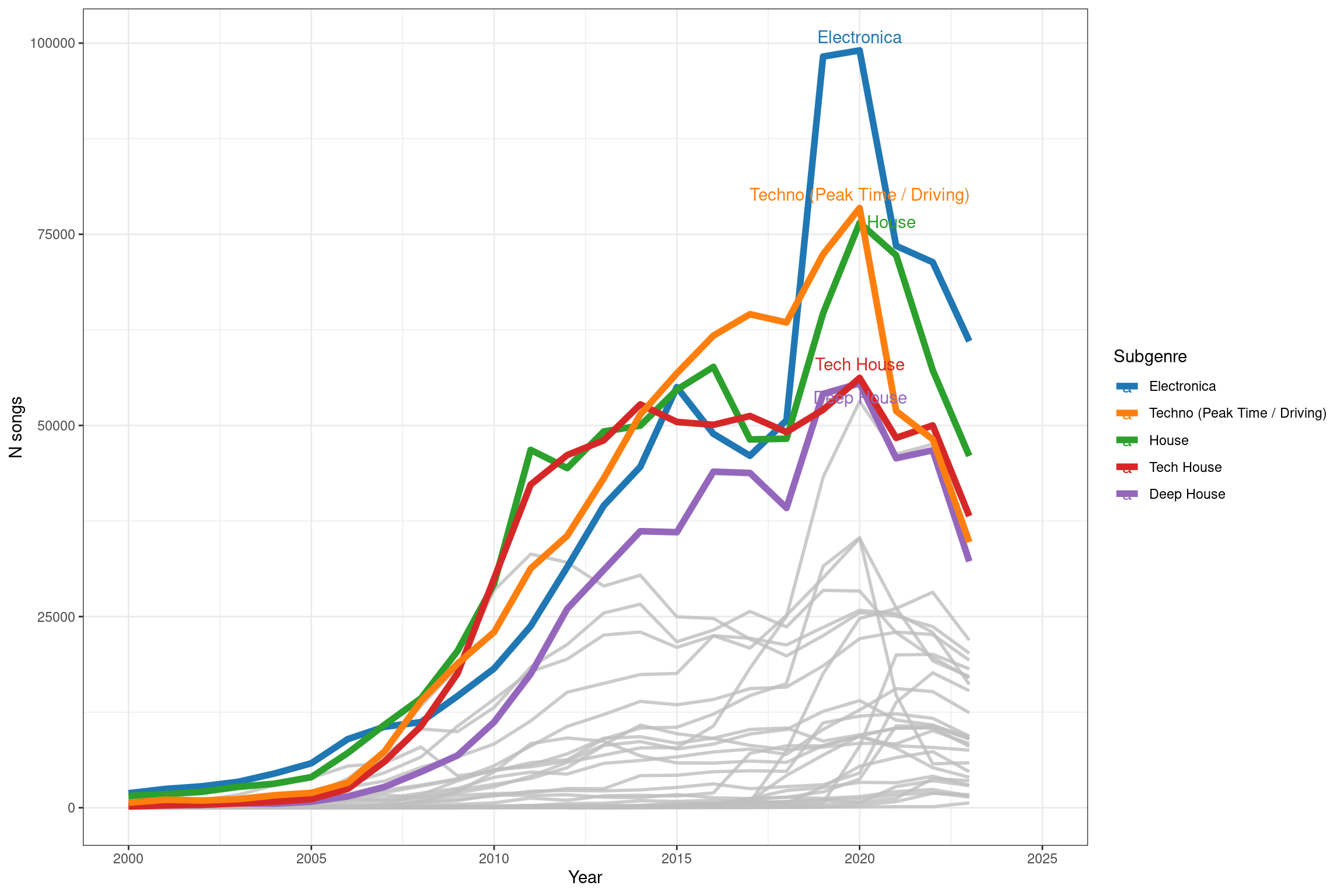
Nos gustaría explorar la distribución de canciones de diferentes géneros a lo largo del tiempo. Para esto primero tenemos que unir las tablas tracks, genre y subgenre. En el diagrama puedes ver las columnas que las unen.
Code
# Union de tablastracks_genre <-merge(tracks,genre[,.(genre_id,genre_name)],by ="genre_id") # Visualiza el número de canciones por genero que se publicaron cada año (release_date) del 2000 al 2024freq_tracks <- tracks_genre[,.N,by = .(genre_name, Yr =format(release_date,"%Y"))]# Opcional: Subconjunto de los géneros con más canciones.labels <- freq_tracks[, .SD[which.max(N)], by = genre_name][order(-N)][1:5]# Generar un vector de 6 colores (el último debe ser gris) para colorear las líneas de los subgeneroscolors <-c("#1f77b4", "#ff7f0e", "#2ca02c", "#d62728", "#9467bd", "gray")names(colors) <-c(labels$genre_name, "other")# Generar una nueva columna que se llame color donde solo aparecen los nombres de los 5 generos más escuchados (en sus filas correspondientes) y el resto de las celdas tiene la palabra "other". freq_tracks[,color :=ifelse(genre_name %in% labels$genre_name, genre_name, "other")] library(ggrepel)freq_tracks %>%ggplot(aes(x =as.numeric(Yr), y = N, group = genre_name))+geom_line(color ="gray", size =1, alpha =0.8)+geom_line(data = freq_tracks[genre_name %in% labels$genre_name], aes(color =factor(color, levels =c(labels$genre_name, "other"))), size =2)+geom_text_repel(data = labels, aes(label = genre_name, color =factor(genre_name, levels =c(labels$genre_name, "other"))), nudge_y=500)+scale_color_manual(values = colors)+scale_x_continuous(limits =c(2000,2025))+labs(x ="Year", y ="N songs", color ="Género")+theme_bw()
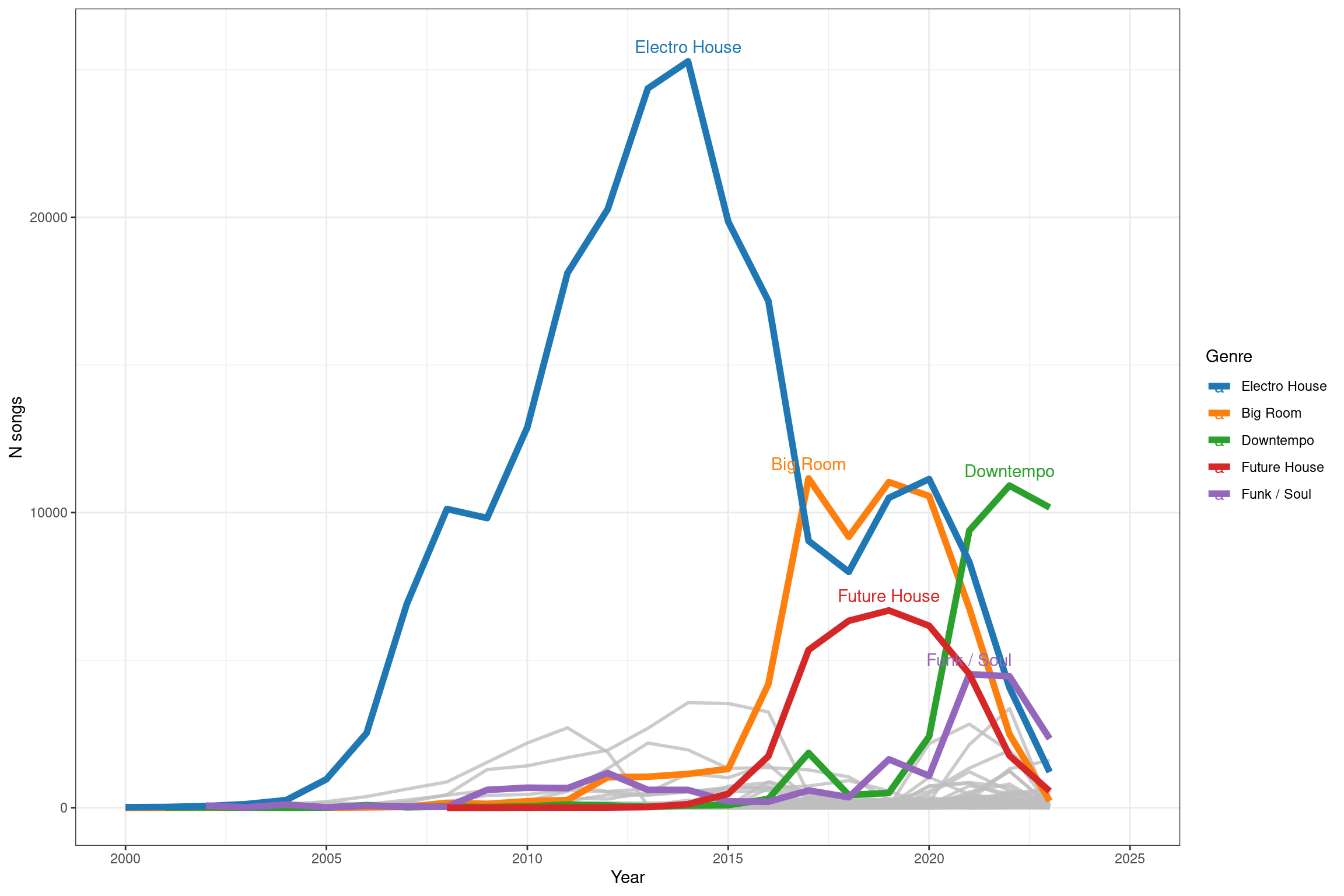
Ejercicio
Genera una gráfica similar en la que muestres la distribución de los 5 subgéneros con más canciones en el tiempo.